扬州城市大运河文化景观的公众意象感知
【目的】面对大运河如今发生的诸多变化,需要以动态、发展的眼光去审视运河遗产的保护与发展实践,全面、客观地认知现代社会对于运河遗产的体验与需求,为大运河遗产在现代社会的保护与利用实践中提供支撑。
【方法】以683篇与扬州运河相关的游记文本数据作为研究材料,运用LDA主题模型构建文化景观意象感知描述体系,半定量化探究公众对于运河文化景观的意象感知特征。
【结果】研究表明:一级感知维度下,扬州运河的意象感知主要从运河的典型景观、游览运河的行程感受及运河文化景观的区域影响力三方面展开;二级感知维度下,与人文景观、自然风光、特色美食、商业服务及服务设施等内容有关的高频词共同构建了较为丰富的运河感知意象,并体现了古运河串联不同城市资源的能力。
【结论】当代社会大运河文化遗产的保护与利用,不仅是对运河遗产物质空间的更新与改造,也是对运河景观风貌及社会个体心理体验等社会空间的重构。该研究结论有助于理解运河文化景观在现代城市语境下的社会角色与地方意义,并为相关城市文化景观风貌塑造提供审慎参考。
关键词:大运河;扬州;文化景观意象;公众感知;LDA主题模型;遗产保护;活态遗产;网络游记;社会空间
引言:大运河遗产保护的当代价值与公众视角
大运河是凝聚中国古代人民治水、理水生态智慧的重要水利设施,也是连通南北地域空间与文明的桥梁[1]。作为世界上唯一仍具有原始功能的“活态”文化遗产,大运河及其周边环境在城市化的影响下,既保留了本身的历史人文特征,也结合沿线城镇的公众需求具备了休憩娱乐、生态建设及文化传承等现代功能。面对大运河如今发生的诸多变化,如何以动态、发展的眼光去审视运河遗产的保护与发展实践,如何合理、客观地认知现代社会对于运河遗产的体验与需求,成为此类线性文化遗产“永葆活力”所需要面对的现实问题。
2019年2月,中共中央办公厅、办公厅印发《大运河文化保护传承利用规划纲要》,明确提出在大运河文化保护传承的工作中,要从其历史脉络及当代价值2个方面来理解运河遗产的内涵与外延。然而,现有大运河遗产研究多关注该类遗产本体内在的、静态的历史特征,以运河遗产的历史变迁[2]、文化特征[3]、物质遗存[4]及沿运河一带的城乡空间格局[5]研究居多;对于其当代价值的研究则相对零散,且相关研究多从景观设计[6]、文保政策[7]、旅游资源开发[8]角度入手,自上而下地研究运河遗产在当今社会的功能与意义,较少涉及遗产使用者对于大运河遗产及其环境利用现状与价值认知的关注。
由于文化遗产的“使用状况”是认定遗产本身当代“身份”的重要因素,而使用者的体验更是评价文化遗产的利用、实践结果优劣的标准之一[9],因此文化遗产使用者与遗产本体间的互动是构建当代遗产价值的重要一环[10],从文化遗产使用者视角开展大运河遗产研究亦具有必要性。
文化遗产的使用者包括地方各级政府、当地居民、外来游客等不同社会群体。其中,文化遗产地的访客和消费者等游客群体作为文化遗产的潜在构建者与传承者[11],在遗产游览过程中所产生的认知、体验和情感等感知内容均可视为遗产意义与价值的组成部分[12],并对文化遗产的内容构成与再现方式产生着重要影响[13],所以识别公众的在地化意象感知特征对于文化遗产的可持续发展具有积极意义。
在此方面,已有部分学者运用词频统计和共现词网络方法,挖掘不同的用户生成内容(usergeneratedcontent)中公众对运河遗产的感知意象[14-15]。但是由于此类方法仅对文本数据中的高频词特征及高频词之间的关系进行分析,缺乏对于高频词所处文本段落及不同文本集合间的主题聚类分析,分析得到的语义较为模糊且易产生歧义,可靠性有待提高[16-17]。
综合上述研究现状,本研究以扬州运河为例,从公众视角梳理、总结扬州运河文化景观的意象感知特征。通过潜在狄利克雷分配(latentDirichletallocation,LDA)主题模型和感知特征维度分类方法相结合的方式,对有关扬州运河的游记文本数据进行主题提取和内容分析,以期提升文本数据分析的语义准确性和可靠性,为相关城市文化景观风貌塑造、大运河文化带建设以及大运河国家文化公园建设提供经验借鉴和数据支持。
1 理论与方法
1.1 LDA主题模型
LDA主题模型是基于无监督机器学习技术,用于提取给定文档内部潜在主题的文本挖掘方法。LDA主题模型将一篇文档视为由若干主题组成的集合,每个主题则视为由若干词语组成的集合。LDA主题模型通过3层贝叶斯概率模型,将“文档-词语”矩阵转化为“文档-主题”及“主题-词语”矩阵,从而得到不同词语在不同主题下的出现概率以及组合模式,实现文档主题聚类的目的。本研究使用Python语言中的Gensim主题模型工具包调用LDA主题模型,完成游记文本数据的主题提取,为发掘扬州运河文化景观意象的公众感知状况提供结构化的专项数据。
1.2 运河文化景观的感知特征维度

虽然主题模型可通过计算文本特征词之间的相关性来识别文档的潜在主题,但确定主题名称及数量仍需要人工判读进行指定[18],且目前学界对于如何提炼主题模型分析结果(即主题的归属与解读)尚未形成统一的标准[19]。现有研究大多需要研究者依照研究目标自行判读分析结果,并主观总结出合适的主题语义,由此导致同一主题模型分析结果在不同研究者的解读下,可能会产生不同的主题归属与解读结果[20]。
因此,考虑到上述问题,本研究在主题模型分析结果的基础上,对每个主题内部的高频特征词(high-frequencycharacteristicword,HCW)进行一级和二级特征维度的划分与标注[21-22],从而提升主题归属与解读的一致性。
考虑到扬州运河作为反映人与环境互动关系的活态遗产,首先,本研究基于文化景观的定义[23-25],将扬州运河的物质环境、区位结构、空间资源禀赋、地方使用者的行为与体验均纳入研究范畴;其次,综合现有目的地意象感知研究成果[26-28],明确意象感知内容,并从认知、情感、行为3个基本层面进行描述;最后,结合游记文本数据的描述特点,设计出涵盖4个一级感知维度和12个二级感知维度的扬州运河文化景观意象感知描述体系(表1)。
在4个一级感知维度中,“地域与空间”和“环境与景观”维度反映公众对城市运河所在区位、环境及景观构成要素的认知状况。其中,“地域与空间”维度主要指的是公众在运河景观游览行程中途经地域的空间区位和环境条件,而“环境与景观”维度反映的是对公众意象感知有直接影响或意义的环境景观空间或要素。“游览与体验”维度表征的是公众在与文化景观互动过程中所产生的行为与情感,是游览方式和景观体验的具象体现。“出行与时间”维度主要是对公众意象感知全程的时序进行刻画,侧重对运河景观游览行程安排内容的描述。
1.3 研究框架

通过整合LDA主题模型及意象感知特征维度,笔者设计了城市运河文化景观意象感知的研究框架(图1),主要从5个方面展开,用于提炼现代社会公众对运河文化景观的意象感知特征。
2 实证研究
2.1 案例选择
本研究将扬州作为研究对象(图2)的原因有三。
1)扬州历史悠久。扬州是一座因运而生、因运而盛的城市,被誉为“中国运河第一城”。无论是从地理单元还是文化圈层方面来看,扬州均为南北汇聚、吴楚相接、雄秀兼佳之地[3]。自元代京杭大运河全线贯通后,扬州漕运繁荣、盐业兴盛,经济繁复而冠盖江南。现存于扬州境内的运河走向与2500多年前的古邗沟路线大部分吻合,与隋唐大运河河道走向更是完全契合。
2)扬州文化遗产丰富。扬州作为中国大运河原点城市、申遗牵头城市,在大运河沿线具有重要的特殊地位。扬州境内现有10处遗址、6段河道被列入世界遗产,这些遗产共同构成了独特且丰富的扬州运河文化资源。
3)扬州具有活态文化遗产特征。扬州古运河现已成为承载当地居民日常生活、城市文化体验、商业服务供给等多元功能的空间载体,其所展现出的鲜明活态文化遗产特征是学界所关注的重要研究内容。因此,选择扬州作为研究对象,对于探索运河文化景观的意象感知特征具有重要的理论与现实意义。
2.2 数据收集与预处理
本研究以携程、马蜂窝和简书作为研究数据的来源网站,以“扬州运河”为关键词在上述网络平台搜索,将得到的相关游记文本作为样本数据,数据覆盖时间范围为2012年1月1日—2021年12月31日。剔除内容重复或属于营销广告的游记文本,最终获得有效游记683篇,平均每篇游记字数为3393字,属于长文本数据,符合LDA主题模型对于所处理数据的基本要求。
在Python中对原始文本数据进行数据清洗,去除其中的字母、标点、特殊字符及网络表情符号等无意义词语。对清洗后的文本数据进行分词,去除如“了”“的”“且”等对文本语义内容表达无贡献的词语。随后,统计上述分词数据中所有词语的词频,并保留词频大于1的词语,最终从683篇有效原始游记文本中共提取出38405个特征词用于后续研究。
2.3 LDA主题模型计算结果
在Python中导入预处理数据后,需设置主题个数(即LDA主题模型中的唯一参数)进行LDA主题模型分析。
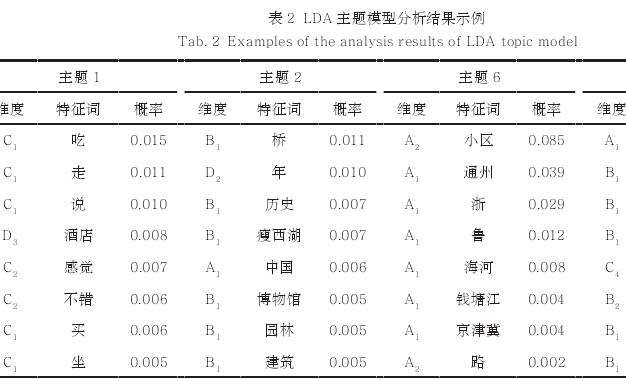
传统的统计方法可能会减少主题模型中的语义特征数量,因此本研究更多地通过定性分析来确定合适的主题个数[18],即通过人工反复判读模型生成结果及每个生成主题所对应的典型文本内容,从中挑选出包含最多语义特征的主题模型个数,最终共得出25个有意义主题(表2)。根据前文分析可知,每个主题均是前文所提取的38405个特征词的概率分布,且该分布在每个主题内部均表现出较为明显的长尾效应。
由于特征词语的概率值越小,表示其对该主题内容的贡献程度越低,因此结合主题模型分析结果,并横向比对各主题特征词的概率分布情况,选择每个主题内部的前100个特征词作为反映该主题内容倾向的高频特征词(图3),将之用于该主题的语义分析。