平原农业基于指标聚类的黑山县生态特征与问题
文章目录导航(TOC)
- 平原农业基于指标聚类的黑山县生态特征与问题定量识别
- 3.1 基于eCognition多尺度分割的研究样本划分
- 3.2 样本生态特征和生态干扰特征统计
- 3.3 样本生态特征和干扰特征的空间聚类
- 3.4 各聚类生态特征与生态问题识别
平原农业基于指标聚类的黑山县生态特征与问题定量识别
将定性的平原农业生态问题定量化是本步骤的关键,恰当的样本划分是实现这一目标的前提。样本是定量计算和制图的基本单元,其分割方法、尺度、形状等会对研究结果产生影响。现有研究通常直接采用土地利用栅格作为单元,或通过行政区、小流域、网格等方式对研究区域进行切分。然而,土地利用单元边界过于破碎,不利于较大尺度的规划管理;小流域、山脊线等自然边界不适于特质平淡的地区,网格、行政区等则会将生态问题不同的斑块纳入同一样本,不利于在地性问题识别。本研究将深度学习领域中常用的多尺度分割引入风景园林规划制图单元,基于研究区域的关键生态要素和生态问题空间分布规律切分样本。进一步将生态特征和生态问题相似的样本进行聚类和制图,实现生态特征和生态问题的聚合与空间表达。
3.1 基于eCognition多尺度分割的研究样本划分
图像分割是深度学习中面向对象的高分辨率影像解译常用的预处理方法,基于多光谱数据特征和给定分割准则,将影像分割为具有相似特征的切片,不同切片光谱特征有差异[19]。基于eCognition的多尺度分割方法以异质性最小为原则,依据波段信息采用模糊分类法将像元聚类为多边形对象[20-21]。基于此,当将多光谱对象由常用的卫星影像变为研究区域的关键生态要素时,则可用于划分研究单元,实现保障样本内的一致性和样本间的差异性的目的。
多尺度分割首先需要构建多光谱栅格数据集。采用ArcGIS波段合成工具,将对黑山县生态修复具有关键意义的生态要素和干扰要素整合为多光谱数据,导入eCognition Developer 9.0软件。第2步为设定波段权重,经过团队讨论和专家评价,强调水网、林网在县域生态空间中的主导性,赋权重为2,其余波段为1。最后调试分割参数,设定试验尺度为10~100,步长为10,固定形状权重为0.1,紧凑度为0.5。对比输出结果,当分割尺度为50时,黑山县域被分为3969个研究样本,尺度适宜,生态差异性明显,可用于生态特征与问题的定量化识别。
3.2 样本生态特征和生态干扰特征统计
划分研究样本后,需统计每个样本中各要素的空间占比,表征其生态特征面临生态干扰的程度,基于ArcGIS中的分区统计功能实现。例如,利用河流沟渠面积占比表征单元内水网的生态重要性,利用水土流失面积占比表征单元内受水土流失影响的程度。将上述统计结果整合为数据集,供聚类使用。
3.3 样本生态特征和干扰特征的空间聚类
聚类是机器学习中常用的非监督分类方式,依据研究样本各维度指标,将给定数据集划分为若干类簇,同类研究单元内部差异尽可能小。在本研究中,通过关键要素占比聚类,实现同组样本生态特征接近、受到生态干扰类型和范围相似,而不同组样本间或生态特征有差异,或面临不同生态问题。
K-Medoids是聚类中最常见的算法,采用欧氏距离作为相似性判断的准则,该算法取样本中最靠近中心的对象,对异常值较不敏感[22],是其最常用的实现方式。假设将包含N个i维度研究单元的数据集划分为K类,各聚类中心点为Ok。首先,在所有样本中随机选择Ok,逐一计算剩余点M到Ok的欧氏距离,将M分配给距离最近的Ok所在类,得到初始聚类。然后,随机选M来替代Ok,记为OM,计算替代前后剩余点到中心点距离变化情况,判断OM是否优于Ok,迭代上述步骤至收敛[22-23]。本研究中上述步骤在R中实现,数据集含3969个样本,被9个维度所描述。聚类前采用最小均方误差法初判类别数。经多次试验,当K值为8时各聚类特征清晰,冗余信息少,因此将样本分为8组具有不同生态特征和问题的聚类。
3.4 各聚类生态特征与生态问题识别
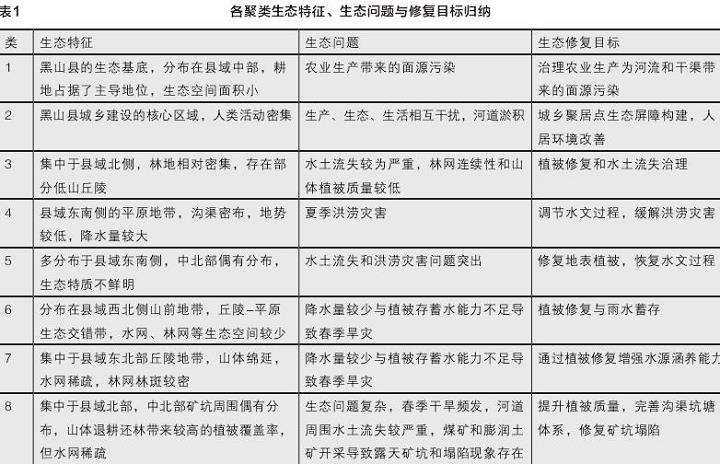
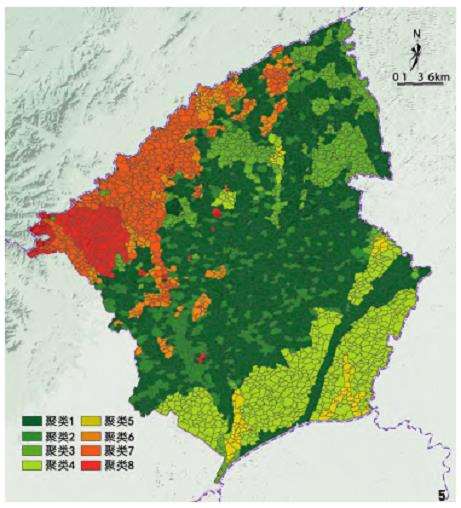
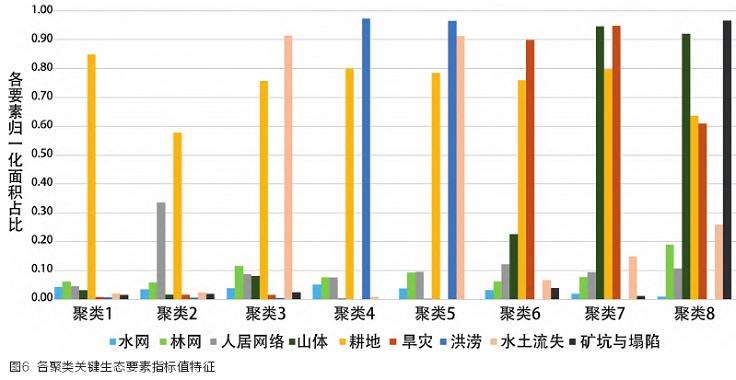
经过关键生态要素识别和聚类,黑山县县域被划分为8类生态特征和生态问题鲜明的聚类。图5、6分别展示各聚类的空间分布和生态要素指标值特征。结合实地调研,总结各聚类的生态特征、生态问题和生态修复目标(表1)。